20+ word2vec embedding python
Overview of Word Embedding using Embeddings from Language Models ELMo 16 Mar 21. What to do after getting each word embedding for sentence 1 6 100 and sentence 2 4100 by assuming 6 word in first sentence 100 is the embedding size and 4 word in second sentence with 100D is embedding.

A Taxonomy Of Word Embeddings Download Scientific Diagram
Transfer learning refers to techniques such as word vector tables and language model pretraining.

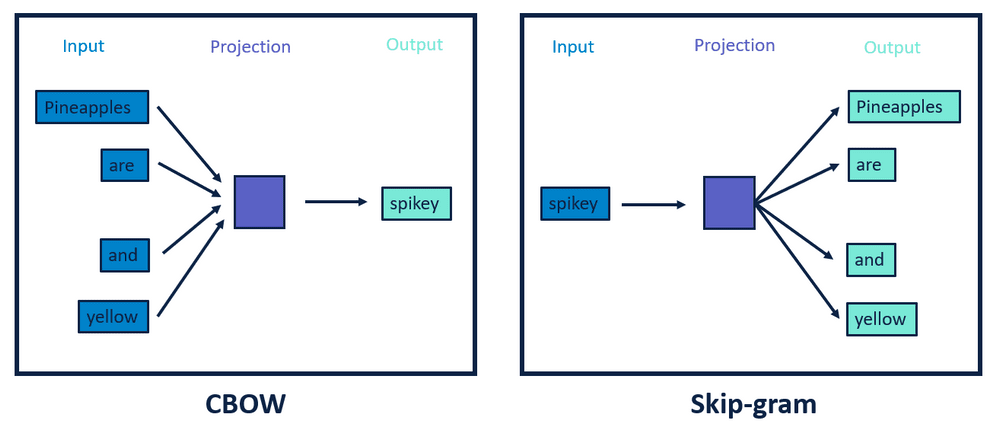
. Gensim is an open-source python library for natural language processing. Python - Print the last word in a sentence. 目录一为什么需要Word Embedding二Word2vec原理1CBOW模型2Skip-gram模型三行业上已有的预训练词向量四用Python训练自己的Word2vec词向量一为什么需要Word Embedding在NLP自然语言处理里面最细粒度的是词语词语组成句子句子再组成段落篇章文档.
1 Filtering Word Embeddings from word2vec. I have a collection of 200 000 documents averaging about 20 pages in length each covering a vocabulary of most of the English language. A common example of embedding documents into a wall.
The underlying concept that distinguishes man from woman ie. Is it possible to re-train a word2vec model eg. These techniques can be used to import knowledge from raw text into your pipeline so that your models are able to generalize better.
To execute this. Cosine similarity and nltk toolkit module are used in this program. Python Reverse each word in a sentence.
The directory must only contain files that can be read by gensimmodelsword2vecLineSentence. The target_embedding and context_embedding layers can be shared as well. Python Word Embedding using Word2Vec.
SpaCy supports a number of transfer and multi-task learning workflows that can often help improve your pipelines efficiency or accuracy. What is Word Embedding. This embedding is an implementation of this paper.
This project provides 100 Chinese Word Vectors embeddings trained with different representations dense and sparse context features word ngram character and more and corporaOne can easily obtain pre-trained vectors with different properties and use them for downstream tasks. Word2Vec using Gensim Library. Pre-trained Word embedding using Glove in NLP models.
In the way doc2vec extends word2vec but also other notable techniques that produce sometimes among other outputs a mapping of documents to vectors in ℝⁿ. Cosine similarity is a measure of similarity between two non-zero vectors of an inner product space that measures the cosine of the angle between them. It is a language modeling and feature learning technique to map words into vectors of real numbers using neural networks probabilistic models or dimension reduction on the word co-occurrence matrix.
Im using Gensim if it matters. Im using a size of 240. This property and other.
Sex or gender may be equivalently specified by various other word pairs such as king and queen or brother and sisterTo state this observation mathematically we might expect that the vector differences man - woman king - queen and brother - sister might all be roughly equal. I will also try to. It is a neural network structure to generate word embedding by training the model on a supervised classification problem used to measure semantic.
Word Embedding is a word representation type that allows machine learning algorithms to understand words with similar meanings. Due to SGT embeddings ability to capture long- and short- term patterns it works better than most other sequence modeling approaches. In this post I will touch upon not only approaches which are direct extensions of word embedding techniques eg.
In this part we discuss two primary methods of text feature extractions- word embedding and weighted word. Text Cleaning and Pre-processing In Natural Language Processing NLP most of the text and documents contain many words that are redundant for text classification such as stopwords miss-spellings slangs and etc. You could also use a concatenation of both embeddings as the final word2vec embedding.
Im using the word2vec embedding as a basis for finding distances between sentences and the documents. GoogleNews-vectors-negative300bin from a corpus of sentences in python. Object Like LineSentence but process all files in a directory in alphabetical order by filename.
Not covered in this post but refer to this paper to see the accuracy comparison of SGT embedding over others. Similarity AB AB where A and B are vectors. So for this problem Word2Vec came into existence.
Class gensimmodelsword2vecPathLineSentences source max_sentence_length10000 limitNone. Chinese Word Vectors 中文词向量. Bz2 gz and text filesAny file not ending.
Working with Word2Vec in Gensim is the easiest option for beginners due to its high-level API for training your own CBOW and SKip-Gram model or running a pre-trained word2vec model. Reshape the context_embedding to perform a dot product with target_embedding and return the flattened result.
Most Popular Word Embedding Techniques In Nlp
Example For Skip Gram Model In Word2vec Download Scientific Diagram
Illustration Of Data Parallelism With Word2vec Download Scientific Diagram

Illustration Of Data Parallelism With Word2vec Download Scientific Diagram
Bidimensional Representation Of Tokens Generated By Word2vec Pca The Download Scientific Diagram
Word2vec Cbow Representation Of Words Are Plotted In This Graph Download Scientific Diagram

Most Popular Word Embedding Techniques In Nlp
Most Popular Word Embedding Techniques In Nlp

Most Popular Word Embedding Techniques In Nlp
T Sne Plot Of 500 Loinc Embeddings Trained Via Word2vec E Dimension Download Scientific Diagram

Different Embeddings Word2vec And Glove Versus Macro 20newsgroup And Download Scientific Diagram

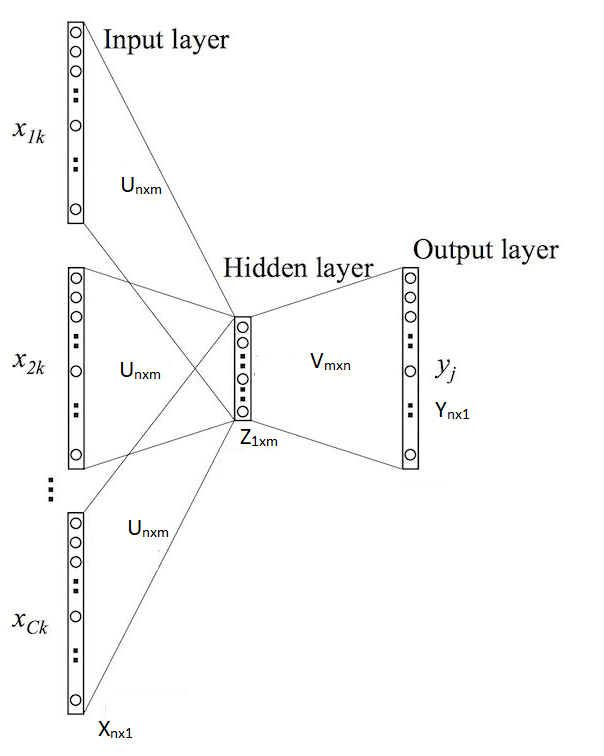
The Skip Gram Model Words Context Model

Clusters Of Semantically Similar Words Emerge When The Word2vec Vectors Download Scientific Diagram

In The Word Embedding Space The Analogy Pairs Exhibit Interesting Download Scientific Diagram

Beyond Word Embeddings Part 2 Word Vectors Nlp Modeling From Bow To Bert Nlp Beyond Words Words

Different Embeddings Word2vec And Glove Versus Macro 20newsgroup And Download Scientific Diagram

Example Of Combining Word2vec With Tfpos Idf Download Scientific Diagram